

Examining the Bitcoin Whitepaper - Part 3/3
A post to understand key concepts behind the famous Bitcoin whitepaper. Part 3/3
What’s this post about?
This is a three part post where I explain concepts included in the famous white-paper that are not introduced nor described beforehand, and are important to have a better grasp of the problems tackled by Bitcoin. They are divided into the same sections of the paper.
This is not a one-stop-shop for Bitcoin or crypto, but a good catch-most of the under-explained concepts in the original whitepaper. Also, this is not financial advise, nor am I trying to evangelize this to you. :)
How to make the best out of this post
I believe the best way to understand the original paper is to have this post by your side, stop here for the tricky and technological concepts, and return to reading the paper. There is no specific order, and you can skip any section (specially the mathy ones).
This is Part 3. Check Part 1 here, and Part 2 here.
Table of Contents
Combining and Splitting Value
Fan-out
Why is there never the need to extract a complete standalone copy of a transaction’s history?

First of all, the BTC blockchain does not have a “balance” at any point.
If A sends a transaction to B, A creates an output for a certain amount of bitcoins. For A to spend those funds, an output script defines a condition to allow such event to occur: to spend the transaction, the spender (A in this case) must sign the transaction’s hash with the private key from A’s address. In this way, A can actually spend it, because A owns that unspent transaction. L
There are other possible scripts, not limited to 1 private key but multiple keys too, forcing other address to participate in the transaction.
So what is the balance I see on my wallet? Well, your wallet is actually showing you all unspent transaction outputs that you are able to spend with your private keys. These individual unspent outputs come from other transactions that are A’s right to spend. Let’s think of an example.
If you have 35 USD in your wallet, you must have a combination of bills for there is no 35 USD bill. For example, one 5 USD bill, one 20 USD bill and one 10 USD bill. Each of these individual bills are unspent outputs. They are values in your favour that you can spend and that you received from previous transactions that are in your wallet.
Let’s say now you want to spend 21 USD on a buffala pizza. You are going to give 1 or more of your unspent outputs to the cashier. So to cover the pizza, you have to give, say, the 20 USD bill and the 5 USD bill. The cashier then gives you 4 USD in change (say coins). This change is, yes, an unspent output, that goes back to your wallet with the rest of the outputs.
The key here is that the totality of the output must match the input. So in our example, you gave the cashier 25 USD, and then 25 USD in total were redistributed accordingly; 21 USD for the pizza place, and 4 USD back to you in change.
Note that, in the real world, if the total output amount is less than the total input amount, the difference is considered the transaction fee and this will go to the miner of the block your transaction will appear in.
If, on the other hand, the output is greater than the input, then the transaction is completely invalid. The difference would be created from thin air. You could give someone value it receive the same amount right back; the “double spend” Satoshi wants to avoid!
All in all, it is not possible to do a thing like “subtract the amount from person A’s balance and add it to person B’s balance”. When making transactions, you basically destroy some outputs to generate new ones.
So, if you didn't have to spend an output entirely, like in an account/balance system, you would need to check every other transaction that also includes that output and make sure the sum wasn't more than it contained, adding a lot of complexity to the validation and development.
Privacy
Unavoidable linking
Why is some linking still unavoidable with multi-input transactions, which necessarily reveal that their inputs were owned by the same owner?
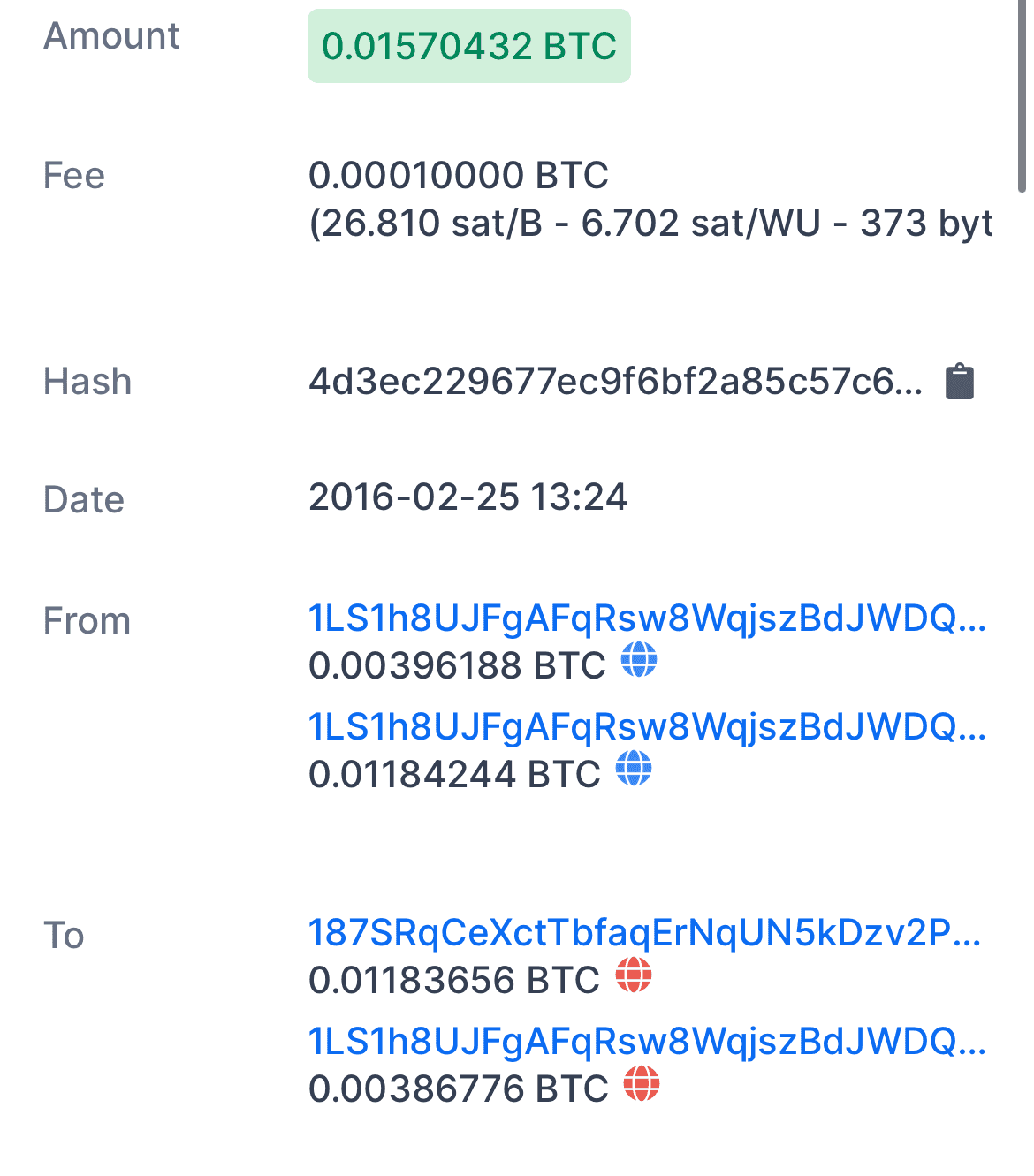
In the transaction from above, 1LS1h8UJ… is both an input and a change address. Most of the transaction funds were sent to 187SRqCe…and the rest went back to 1LS1h8UJ… with 0.01580432 BTC.
This is a bad practice for privacy reasons. Someone watching can tell that the sender controls 1LS1h8UJ (used as input and change address).
If no address reuse was present then someone could not tell which was the destination address and which was the change address.
Always create new addresses for change.
Calculations
What is a Binomial Random Walk?

A random walk is sort of like the steps of a drunk person. One cannot figure out if the next step goes forward or backward (or left or right).
Formally, in a random walk, we start at some starting position, usually 0. Then subsequent steps are taken by looking at the current value and adding some random value to it.
In reality, steps look random, but are heavily dependent on previous values, namely the most recent one.
Why is q/p the probability the attacker catches up from 1 block behind?
Nakamoto isn’t analyzing whether the economics work out: it may be that the attacker spends more on mining than is recovered from the double spent transaction; or it may be that the Coinbase reward from announcing a tremendous number of new blocks is worth more than the double spent transaction. Nakamoto’s goal is instead solely to analyze the worst-case scenario where the attacker spares no expense in running their existing mining power to win the Gambler’s Ruin.
Let p be the mining power and probability that the honest miners find the next block, and let q be the attacker’s mining power. We define q + p = 1, since we assume either only the attacker or honest miners will win a block each round (and not some late comer or third-party).
If the attacker has unlimited resources for mining and stops when he reaches z, then we can use Eq. 22 from the paper quoted previously.
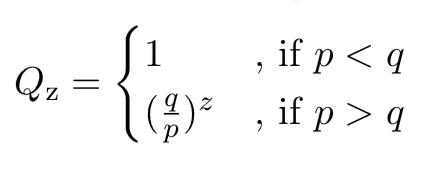
It’s worth noting an error by Nakamoto here. We aren’t interested in Qz, the probability that the attacker will simply catchup. Instead, Nakamoto should have calculated Qz+1, the probability of the attacker going one past the honest miners.
There are a few limitations we need to be aware of. First of all, it’s a challenge for the merchant to determine the attacker’s mining power q. It’s always possible that a previously unknown miner or an existing one could dedicate new resources to double spend attacks. The Fischer, Lynch, and Paterson (FLP) impossibility result tells us that Satoshi’s algorithm can never reach consensus. At any point in time, the last block on the chain is only an estimate of what consensus will be in the future.
Second, the model is a little strange in that the budget for the attacker is infinite for playing the Gambler’s Ruin; yet, the attacker has limited computational power. Satoshi was perhaps attempting to quantify the worst case for each value of q.
Comments
Thank you for your comment! Under review for moderation.